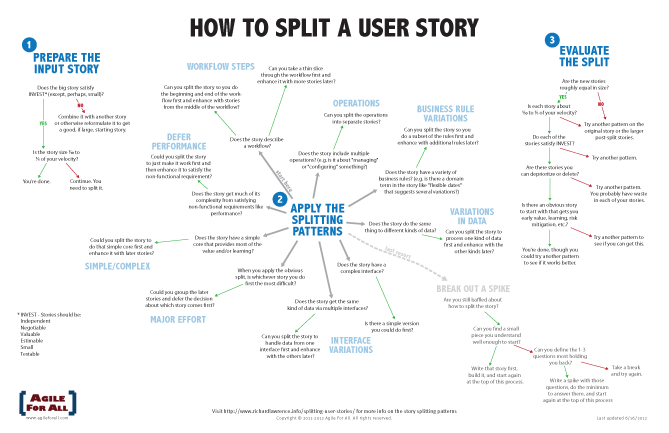
Recentemente ho avuto occasione di seguire un workshop di Sally Elatta dal titolo “4 levels of Agile Requirements”.
L’idea centrale della relatrice – fondatrice di Agile Transformation e Agile coach – è che sia fondamentale approcciare i requisiti agili secondo diversi gradi di astrazione.
Questo modus operandi non è una novità.
Abbiamo già parlato di come l’introduzione di una gerarchia nel Product Backlog possa essere d’aiuto sia per il team sia nei rapporti con gli stakeholder di progetto.
Sally Elatta ripropone questa idea sottolineando l’importanza di avere punti di vista sul progetto che vanno dal generale al particolare, ovvero:
– epiche
– funzionalità
– user stories
– singole attività (task)
Considerare i requisiti secondo questi 4 livelli di astrazione consente di legare le singole attività implementative con la “big picture” del progetto e dare così valore alle scelte che dovremo effettuare nel corso dello sviluppo.
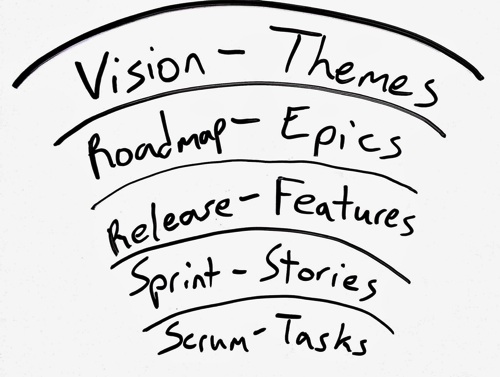
La continuità tra i vari livelli è ben rappresentata nell’immagine.
In relazione al Backlog ci interessa concentrare l’attenzione sui 3 livelli centrali.
USER STORIES
Le user story rappresentano il secondo livello dal basso, quello in cui propriamente avviene l’azione o interazione.
Descrivono brevemente ciò che il sistema può fare per risolvere un problema specifico di un utente ben definito.
La caratteristica principale delle storie è essere focalizzate sul valore che producono per il soggetto, a differenza dei singoli task che sono invece una segmentazione delle attività ai fini della lavorazione da parte del team.
FUNZIONALITA’
Ad un livello superiore di astrazione rispetto alle user stories troviamo le funzionalità (features), che costituiscono una descrizione più tradizionale del comportamento del sistema.
Sono il livello intermedio tra i bisogni dell’utente e la soluzione progettuale complessiva.
Il concetto di funzionalità ha dal mio punto di vista un enorme pregio: collega le singole attività portate avanti dal Team Scrum con una terminologia utilizzata abitualmente da figure professionali quali Program Manager, Product Manager e manager in generale.
Mediante un elenco di funzionalità siamo in grado di descrivere il nostro progetto con un discreto grado di approfondimento e di spiegarlo anche ad interlocutori non avvezzi alle metodologie agili.
In alcune realtà aziendali di dimensioni medio-grandi anche i team di sviluppatori potrebbero essere organizzati intorno a queste feature.
EPICHE
Infine le epiche rappresentano il livello più alto di espressione del bisogno di un utente.
Sono i pilastri della big picture, le caratteristiche costituenti.
Le epiche sono i primi elementi che emergono dal concept di progetto. Si tratta di storie di grandi o grandissime dimensioni che
permettono di comunicare il perimetro di progetto in poche battute ma non consentono di effettuare una stima iniziale dato l’elevato livello di astrazione.
Il collegamento tra questi 3 livelli – storie, funzionalità ed epiche – ci consente di avere maggiore controllo sullo stato di avanzamento del progetto ed offre una chiave di lettura di immediata comprensione agli interlocutori.
Per questo motivo può essere molto utile verificare la consistenza del backlog salendo e scendendo attraverso questi 3 livelli.
Facciamo qualche esempio di “prova del 9“:
- Possiamo ricondurre tutte le user stories ad un’epica corrispondente?
Se non è così probabilmente potremmo avere “lavoro sommerso” e sprint goal poco definiti. - Ci sono epiche a cui sono collegate pochissime user stories?Verifichiamo di aver compreso bene le aspettative degli stakeholder. Potremmo aver perso qualcosa per strada o non aver spacchettato correttamente il lavoro.
- Siamo in grado di tradurre il backlog della release in una lista di funzionalità? Possiamo sintetizzare con una percentuale di avanzamento a che punto sono queste feature ?
Potreste accorgervi – come nel mio caso – che non state utilizzando coerentemente o con continuità tutti e 3 i livelli.
Non resta che ispezionare e adattare il backlog, in perfetto spirito agile…